What happened
Before my days working in collections full-time, I worked as a liaison librarian. In that role I was responsible for many things for my departments: outreach, teaching, reference, data and research support, and collections. The large number of responsibilities and duties leaves little time for in-depth and proactive collections management.
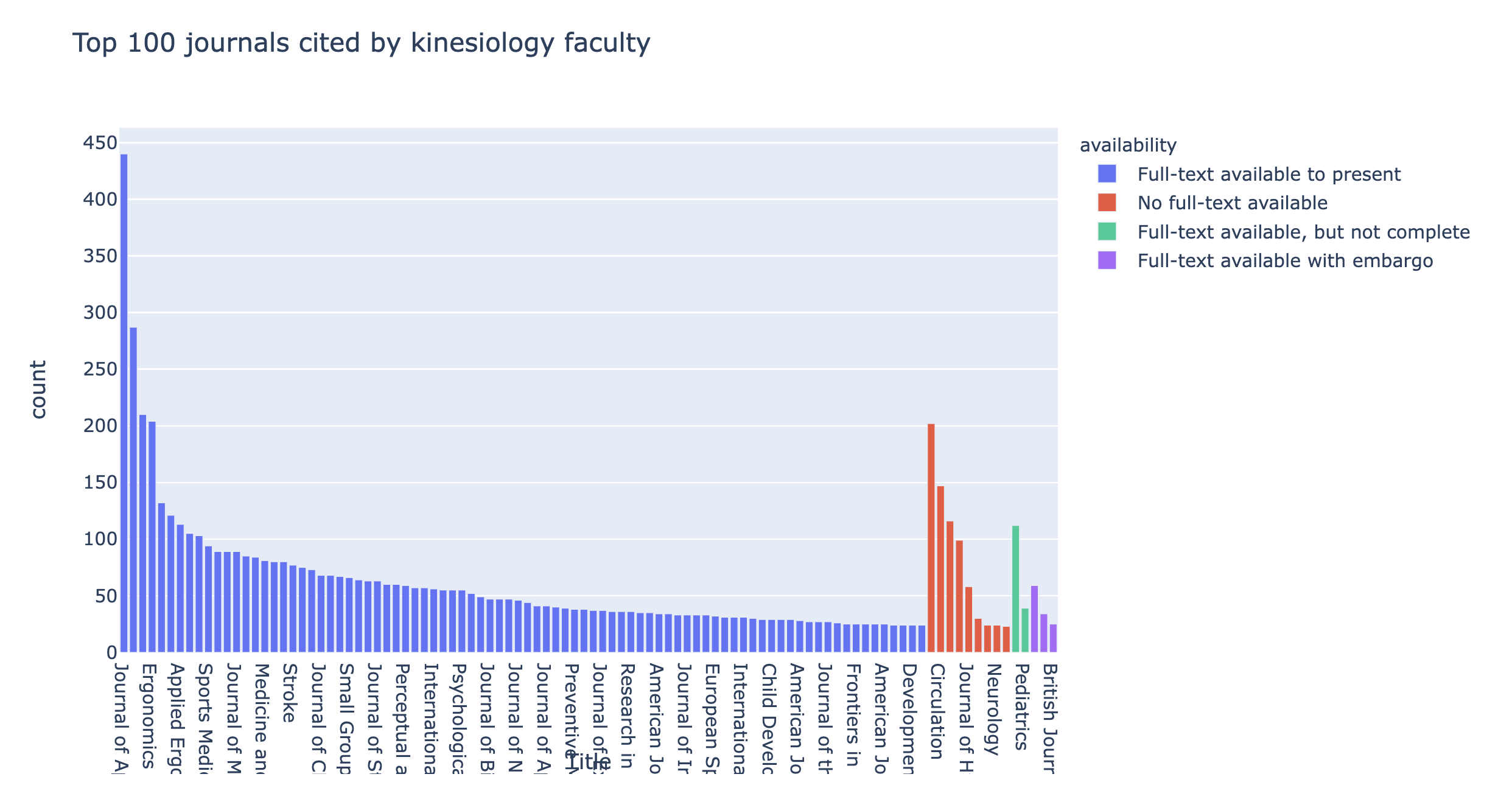
Common practice for evaluations relied heavily on usage data provided by the vendor (when available), consultation and personal judgement. Bibliometric approaches to collections evaluation, like those used in large-scale projects such as the Elsevier cancellation at the University of California, or the CRKN Journal Usage Project, use other metrics to evaluate electronic journals. These include data points such as identifying which journals the campus author’s publish and cite. Such metrics are available in some form from proprietary reports that universities can purchase, such as from 1Science (Elsevier) or from InCites (Clarivate Analytics), but the underlying data is available from the same citation indexes that many universities already subscribe to (e.g., Scopus, Web of Science). In this project, I sought to create these metrics programmatically by using existing citation indexes and open source data sources.
Using the API for Scopus, a resource we already subscribed to, I was able to download all the publications by UWindsor faculty members. Refining this dataset, I can parse out bibliographic information for the journals and create a list of authored journals. With the API, I also identified all the referenced sources from the articles, and after refining, a list of the cited journals. I wrote a script in Python to do this automatically and utilized the API for the library link resolver to grab information about the library holdings for the journals. As a result, this project enabled me to identify what journals we subscribe to, which ones we don’t subscribe to, and which ones we have embargoed access to — for both journals published in and journals cited.
Leveraging Jupyter Notebooks, free and open source software, I created dynamic reports for different subject areas. I offered to create reports for any of my colleagues who were interested. I also openly shared the code with librarian colleagues across Canada and the U.S., presenting this at conferences. Librarians have been interested in my methodology and I’ve been invited to present this at McMaster Library and to consult on this process.